
![蜂巢数据[网页数据采集分析] v1.2 免安装版](http://pic.9upk.com/soft/UploadPic/2015-12/2015121413464525263.gif)



WebHarvy是一款非常好用的网页数据采集工具。采集网页数据,久友下载站小编为你推荐 WebHarvy 。这是一款网页数据获取软件,可以通过该软件,直接在网页上选择需要选择的资源,也可以将整个网页保存为html的格式,从而提取网页里面所有文本以及图标内容,WebHarvy破解版能够自动提取文字,图片,网址和电子邮件从网站,还可以多种格式保存从网页中提取数据,WebHarvy特别版特别的使用,赶快了解.
软件特色:
支持在浏览器上复制链接搜索
支持配置对应资源项目搜索
可以使用项目名称以及资源名称查找
SysNucleus WebHarvy可以轻松提取数据
提供更高级的多词语搜索以及多页搜索
SysNucleus WebHarvy可以让您分析网页上的数据
可以显示从一个HTML地址上分析连接数据
可以延伸到下一个网页页面
可以指定搜索数据的范围以及内容
可以将扫描的图片下载保存
破解教程:
1、双击Setup.exe,点击next
2、勾选I accept,点击next
3、选择安装路径,点击next
4、点击install
5、安装完成点击finish退出,不要运行软件
6、将安装包中Fix文件夹下的WebHarvy.exe复制到软件安装目录中,点击替换目标中的文件
7、破解完成
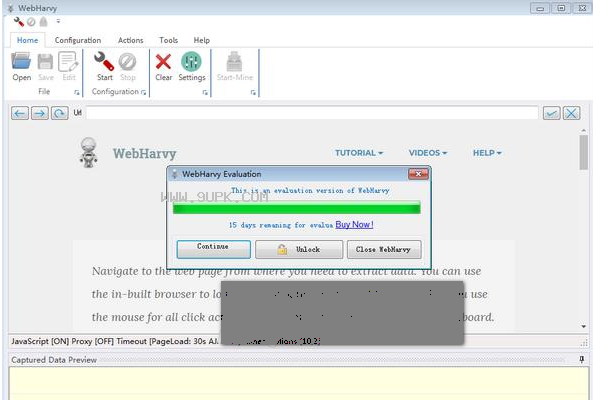
软件功能:
从多个页面提取
通常网页显示数据,如在多个页面中的产品目录。 WebHarvy可以自动抓取并从多个网页中提取数据。只是指出了“链接到下一页和WebHarvy网站刮板将自动刮从所有页面的数据。
基于关键字的提取
基于关键字的提取可让您捕捉从搜索结果页面输入关键字的列表数据。您创建的配置将被自动重复所有给定输入关键字,而挖掘的数据。可以指定任意数量的输入关键字
通过代{过}{滤}理服务器提取
提取匿名和防止提取网络软件被封锁的Web服务器,您必须通过代{过}{滤}理服务器访问目标网站的选项。可以使用一个单一的代{过}{滤}理服务器地址或代{过}{滤}理服务器的地址列表。
提取分类
WebHarvy网站刮板允许您从一个链接列表,从而导致一个网站内的相似页面抽取数据。这使您可以使用一个单一的配置刮网站内的类别或小节。
使用正则表达式提取
WebHarvy可以应用正则表达式(正则表达式)在文本或网页的HTML源代码,并提取去匹配的部分。这种强大的技术为您提供了更多的灵活性,同时拼抢的数据。
视觉点和点击界面
WebHarvy是一个可视化的网页提取工具。其实完全没有必要编写任何脚本或代码用来提取数据。使用WebHarvy的内置浏览器浏览网页。您可以选择用鼠标点击来提取数据。它是那么容易!
智能识别模式
自动识别网页中出现的数据模式。所以,如果你需要从一个网页刮项目(姓名,地址,电子邮件,价格等)的列表,你不需要做任何额外的配置。如果数据重复,WebHarvy会自动刮。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。 WebHarvy网站刮板的当前版本允许你导出的刮数据作为XML,CSV,JSON或TSV文件。您还可以刮下数据导出到一个SQL数据库。

 定时关机3000
定时关机3000![Wise Auto Shutdown[电脑定时关机软件] 1.52 中文免安装版](http://pic.9upk.com/soft/softico/2016-9/20169210354518834.png) Wise Auto Shutdown[电脑定时关机软件] 1.52 中文免安装版
Wise Auto Shutdown[电脑定时关机软件] 1.52 中文免安装版 准点定时关机工具 1.1.0.3正式免安装版
准点定时关机工具 1.1.0.3正式免安装版 苦菜花关机助手2016 2.9.0.3中文免安装版
苦菜花关机助手2016 2.9.0.3中文免安装版 布谷鸟定时关机器 1.11免安装版
布谷鸟定时关机器 1.11免安装版 定时关机助理 3.1免安装版
定时关机助理 3.1免安装版 【定时关机程序】360度定时关机专家 2.5.1绿色版
【定时关机程序】360度定时关机专家 2.5.1绿色版 Dont Sleep 3.89英文绿色版
Dont Sleep 3.89英文绿色版 飞速流量专家是一款集合众多功能为一体的SEO优化工具,飞速流量专家是刷网站关键字排名,网站排名优化,刷网站流量软件功能强大,飞速流量专家可适用于刷网站综合排名,刷百度相关搜索,关键词排名等,软件以互刷模式进行智能...
飞速流量专家是一款集合众多功能为一体的SEO优化工具,飞速流量专家是刷网站关键字排名,网站排名优化,刷网站流量软件功能强大,飞速流量专家可适用于刷网站综合排名,刷百度相关搜索,关键词排名等,软件以互刷模式进行智能...  石青垃圾站建站养站大师是一款独特的SEO软件,他通过把个人博客模拟为CMS信息发布网站,从而达到吸引搜索引擎的目的,带来大量流量为建站者带来广告收益。
建站者往往都希望能够快速而简便的建站,并在少数的时间内有较...
石青垃圾站建站养站大师是一款独特的SEO软件,他通过把个人博客模拟为CMS信息发布网站,从而达到吸引搜索引擎的目的,带来大量流量为建站者带来广告收益。
建站者往往都希望能够快速而简便的建站,并在少数的时间内有较...  石青留言评论群发群顶大师是一款SEO高级工具。专门用来发送产品、网站和广告信息,使用本软件可以在短期内使你 发送的信息占领互联网,并可以把你站点在搜索引擎上做一个很好的排名。
本软件是网络推手,SEO者,网赚者...
石青留言评论群发群顶大师是一款SEO高级工具。专门用来发送产品、网站和广告信息,使用本软件可以在短期内使你 发送的信息占领互联网,并可以把你站点在搜索引擎上做一个很好的排名。
本软件是网络推手,SEO者,网赚者...  nfopad 是一个文本浏览编辑工具 支持nfo 文件
该工具独特的地方在于能够自动识别ansi 和ascii编码
nfopad 是一个文本浏览编辑工具 支持nfo 文件
该工具独特的地方在于能够自动识别ansi 和ascii编码  超级软路由(X-Router)是高性能软路由系统,普通PC机能支持几千台机器的同时上网。能够抵抗内外网机器的任何攻击;支持多个线路的接入;具有自动带宽调节功能,2M带宽可带15-20台PC上网;有WEB认证、PPPOE认证功能;具有...
超级软路由(X-Router)是高性能软路由系统,普通PC机能支持几千台机器的同时上网。能够抵抗内外网机器的任何攻击;支持多个线路的接入;具有自动带宽调节功能,2M带宽可带15-20台PC上网;有WEB认证、PPPOE认证功能;具有...  QQ2017
QQ2017 微信电脑版
微信电脑版 阿里旺旺
阿里旺旺 搜狗拼音
搜狗拼音 百度拼音
百度拼音 极品五笔
极品五笔 百度杀毒
百度杀毒 360杀毒
360杀毒 360安全卫士
360安全卫士 谷歌浏览器
谷歌浏览器 360浏览器
360浏览器 搜狗浏览器
搜狗浏览器 迅雷9
迅雷9 IDM下载器
IDM下载器 维棠flv
维棠flv 微软运行库
微软运行库 Winrar压缩
Winrar压缩 驱动精灵
驱动精灵