

SBWebCamCorder是一款简单好用的数据文件下载软件。一款专业的数据文件下载工具SBWebCamCorder。它是一种数据文件下载工具,旨在允许用户从网站的单个文件下载所有内容,包括网站的所有页面和图像。它还具有重复捕获功能,使您可以重复捕获随时间变化的图像,例如网络摄像头图像;除了用户可以想到的之外,此工具还具有扩展的设置页面,其中包含启用自动重启和代理服务器支持的选项,以及重复拒绝功能,该功能将拒绝重复文件并记住重复的URL。蜘蛛设置允许用户确定是捕获单个网页还是捕获整个网站;用户还可以根据根页面的深度来限制链接;需要它的用户可以下载体验。
软件功能:
捕获任何单个文件
捕获包含所有嵌入式图像的页面
支持网站访问,并通过蜘蛛设置捕获网站上的所有页面
捕获时变数据,例如WebCams
SBWcc被设计为通用网站下载器,它可以执行以下所有操作
从包含所有图像的网站或页面捕获单个文件
可以访问所有网站并捕获网站上的所有页面
重复捕获并编号随时间变化的数据,例如WebCam(因此名称为WebCamCorder)
根据大小或内容类型限制下载
SBWcc有哪些特殊功能
包含内置的缩略图(和全屏)JPEG查看器,
允许您在下载文件时查看它们。
全屏JPEG查看器支持幻灯片放映和图像调整大小功能
安装步骤:
1.用户可以单击本网站提供的下载路径下载相应的程序安装包

2.只需使用解压功能打开压缩包,双击主程序进行安装,弹出程序安装界面

3.您可以单击浏览按钮根据需要更改应用程序的安装路径
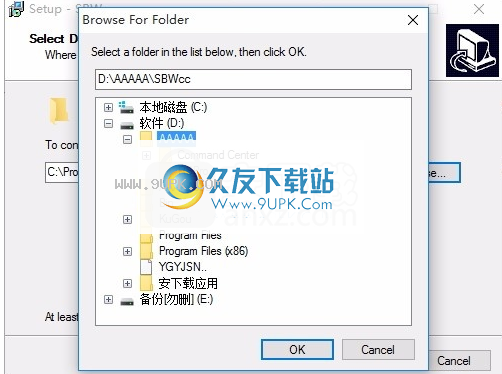
4.弹出以下界面,用户可以直接使用鼠标单击下一步按钮
5.现在您准备安装主程序,单击安装按钮开始安装。
6.弹出应用程序安装进度栏的加载界面,等待加载完成
7.按照提示单击“安装”,弹出程序安装完成界面,单击“完成”按钮
软件特色:
功能齐全的共享软件-没有不完整的功能,没有过期。
内置全屏和缩略图JPEG图像查看器,实时显示传输状态。 (适用于图片或摄像头网站)
根据字节大小拒绝数据(非HTML)文件-自动跳过太大或太小的文件。
可以检测重复和/或重命名具有不同内容的文件。 (对于用于捕获随时间推移相同文件中的更改的WebCam有用)
手动队列查看器和编辑器,允许高级用户在下载不需要的页面之前手动删除它们
您可以限制要遵循的深度长度
您可以仅在需要时将链接限制为正向
有过滤器可以控制下载哪些类型的页面(文本,图像,应用程序,视频,音频等)
身份验证允许您配置付费站点的名称和密码。
使用说明:
您在网络浏览器中看到的“页面”通常由几个不同的部分组成:
页面本身的文本为HTML格式。 (主文件,由您提供的URL指定)
嵌入图像,每个图像存储为单独的文件
URL链接到其他页面。
当浏览器加载页面时,它首先加载HTML文本文件。它解析文件,然后请求每个图像,每个图像作为一个单独的文件。关键是您在网络浏览器屏幕上看到的内容包含许多文件。
所有Web文档均由统一资源定位符(URL)指定。将URL视为文件的地址或“文件所在的位置”。要获取特定文件,您需要知道其URL。例如,示例URL是http://www.newsrobot.com/,这是我的网站地址。所有WWW URL均以前缀“ http://”开头。
默认设置:
SBWcc已预先配置为大多数人想要执行的默认选项:爬网整个站点并将所有文件下载到硬盘驱动器。如果要将SBWcc配置为仅下载单个文件或包含图像的单个页面,则必须按照以下部分中的说明更改某些配置选项。新手的几个常见问题:
默认情况下,SBWcc将
l将Web服务器的目录结构复制到硬盘上。因此,如果将下载路径设置为c:\ program files \ sbwcc,然后下载页面http://www.myhost.com/dir1/page1,则该页面最终将存储在c:\的硬盘驱动器上程序文件\ sbwcc \ dir1 \ page1。关键是:如果您不熟悉Windows文件系统,那么导航到所需文件可能会有些困惑-我的建议是使用Windows资源管理器,如果您感到困惑,请浏览。
您也可以在“设置/下载”页面中取消选中该选项,以使SBWcc将所有文件填充到同一目录中。这消除了上面的问题,但意味着您下载的所有内容都集中了(有点混乱!)
爬网整个站点通常会花费很多时间并下载大量文件。尽量限制您的http://规范,以获取所需的文件。
捕获单个WWW文件:
时您可能想从网络捕获一个且只有一个文件。通常,这是如果您知道所需文件的确切URL。方法如下:
选择“运行”选项卡,然后在顶部的“ URL”框中键入URL。
选择“设置/蜘蛛”选项卡,然后在“蜘蛛方法”框中选择“单个”按钮。
选择“运行”选项卡,然后按<开始>
您输入的URL将被下载并存储在硬盘驱动器上。
使用图像捕获页面:
如果要捕获页面以及该页面中存储的所有图像,请使用这种情况。这将生成多个文件,一个用于页面文本,一个用于每个图像,一个JPEG / GIF文件。进行如下:
选择“运行”选项卡,然后在“ URL”框中键入URL。
选择“设置/蜘蛛”选项卡,然后在“蜘蛛方法”框中选择“页面”按钮
选择“运行”选项卡,然后按<开始>
首先下载页面文本并将其另存为HTML文件,然后下载并将每个图像另存为GIF或JPG文件。
搜索整个站点:
爬网是指请求页面然后跟随其链接以获取其他页面的过程。爬网可以返回很多文件,因为很难确切知道将包含哪些文件。当您知道要将整个网站(包括所有页面,图像和链接)下载到计算机时,爬网非常有用。进行如下:
选择“运行”选项卡,然后在“ URL”框中键入URL。
选择“设置/蜘蛛”选项卡,然后在“蜘蛛方法”框中选择“蜘蛛”按钮。
选择“运行”选项卡,然后按<开始>
将首先下载您输入URL的页面,然后下载所有图像。然后,将跟随每个链接以产生更多的页面和更多的图像。
默认情况下,“蜘蛛”选项配置为仅捕获您输入的站点中的页面。例如,如果您输入“ http://www.newsrobot.com/”,则仅跟随www.newsrobot.com上的链接。这样可以防止Spider算法进入其他潜在的意外站点并下载其内容。您可以通过选中“设置/蜘蛛”选项卡上的“在蜘蛛爬行期间允许非现场页面”选项来覆盖此行为。选中此选项可能会导致SBWcc永久运行,并请求大量页面,因此应谨慎使用。
捕获WebCam输出:
网络摄像头通常是向Internet提供实时图像的摄像头。网络摄像头有很多,包括:
风景相机
办公摄像机
奇怪/奇怪的相机(宠物,房屋等)
成人相机
通常通过WWW浏览器访问这些摄像机。通过浏览到相机,您可以查看站点上当前发生的情况,并且当相机将新数据馈入nternet时,图像将自动更新。
但是,有时您希望将图像从相机“捕获”或“记录”到您的个人计算机上,以便以后查看。这样,您可以稍后查看数据,并查看记录时是否发生了有趣的事情。由于所有图像都存储在本地硬盘驱动器上,因此可以更快地离线查看它们。
第一步是确定要捕获的摄像机的URL。这个非常重要:
您应该使用图像本身的URL,而不是显示图像的页面的URL。
确定“图片URL”的方法如下:
在浏览器中转到网站
查找您要捕获的网络摄像头图像。右键单击图像中间。您获得的菜单将取决于您使用的是Microsoft Internet Explorer还是Netscape Navigator。
如果您使用的是Internet Explorer,则将看到一个菜单,其中包含一个名为“属性”的项目。点击这个。您将看到一个对话框,其中包含有关图像的信息,其中包括一条显示“地址(URL)”的行。这是图片的网址
如果您使用的是Netscape Navigator,您将看到一个包含名为“查看图像”的菜单。点击它。图像将扩展为全屏
cren显示,并且在Netscape Navigator窗口中显示的URL将是图像的URL。
如果您不知道“图片URL”,那么不用担心-如果您为它提供了页面URL,SBWcc仍然可以使用。您将下载一些不必要的其他信息。以下是下载步骤:
选择“运行”选项卡,然后在“ URL”框中输入URL。尽可能使用图片网址而不是页面网址。
选择“设置(下载)”选项卡。如果您在步骤#1中使用了图片网址,请选中“单个”复选框,否则请选中“页面”复选框。
选择“设置(常规)”选项卡。您需要启用“自动重启”复选框,并在“延迟”字段中输入图片之间的近似延迟。我将在下面进一步讨论。
选择“运行”选项卡,然后按<开始>
SBWcc将下载您输入的URL。
下载完成后,SBWcc将暂停一段时间,该时间等于您在步骤3中在延迟字段中输入的时间。延迟完成后,SBWcc将重新启动,然后再次下载映像并保存更改后的图片。
大多数网络摄像头不会立即更新其提要-在大多数情况下,提要会定期更新,例如,每30秒更新一次。因此,以比每30秒一次的速度下载的速度没有意义,因为任何较快的速度都会产生重复的图像。
这是延迟设置的目的。根据您的想法设置图片更新之间的延迟时间。大多数WebCam网站都会在其页面的某个位置包含延迟率的估计值。
如果您尝试下载图像的速度快于网站更新图像的速度,则会收到重复的图像。 SBWcc自动查找重复项,并且不会将其保存到您的计算机中。
设置选项卡分为几个子选项卡,分别代表配置的不同方面:
常:其他选项
下载:下载目录和相关设置
重复项:重复检查器
蜘蛛:选择蜘蛛整个网站
这些内容将在下面分别讨论:
一般:
自动重启。主要用于每次您请求内容时都会更改的网站(例如网络摄像头)。在指定的时间间隔过去之后,自动重启将导致SBWcc重新下载页面。
代理服务器。在某些LAN设置中使用代理服务器,其中一台计算机充当LAN上所有计算机的Web中介。
下载:
下载路径。下载路径是所有下载文件都放置在计算机上的位置。
将URL附加到路径。选中此选项将导致在硬盘驱动器上创建与网站结构匹配的目录结构。取消选中此选项会将下载的所有文件放在一个目录中。
重复:
检查重复项。这控制重复检查器的模式。可以将其设置为“不拒绝重复”,在这种情况下,请不要拒绝任何重复。 “拒绝所有重复项”,在这种情况下,将拒绝所有重复项,或“仅拒绝未修改的内容”。如果选中了后一个选项,则SBWcc将使用Web服务器验证每个重复项是否已更改。尽管这仍然需要很多时间,但比重新下载所有内容要快得多。
网址已被记住。这指定了重复检查器数据库中当前存在的URL数。您可以使用清除按钮清除其中的任何一个或全部。
蜘蛛:
蜘蛛法。这控制了蜘蛛算法的功能:
单身:仅下载您指定的页面。
页面:您指定的页面及其所有图像将被下载,但不会跟随超链接。
蜘蛛:SBWcc将下载您指定的页面,所有图像,然后跟随每个超链接。这将一直持续到所有超链接
直到他们筋疲力尽。
蜘蛛选项
场外图片。如果当前页面包含位于另一台服务器上的图像,则将下载该图像。
异地页面。如果当前页面包含指向位于另一台服务器上的页面的超链接,则将下载该页面。
仅转发链接。如果选中,则仅跟踪比当前目录更深的目录中的链接。例如,如果当前页面是http:// foo / bar / sam,它将跟随http:// foo / bar / sam / joe,但不会跟随http:// foo / bar / tom。
将链接的图像视为内联。许多面向图像的站点都包含指向JPEG / GIF图像的链接。单击链接时,将获得全屏图像。但是,从技术上讲,该图像仍然是超链接,并且SBWcc通常将其视为普通超链接。如果选中此选项,则作为超链接包含的JPEG / GIF图像将具有特殊状态,并被视为嵌入式图像。 (适用于图片网站)
最大链接深度。 SBWcc跟踪每个链接的深度。在蜘蛛模式下,SBWcc将继续跟踪链接,直到耗尽所有链接为止,这可能需要很长时间(或无限长)。您可以指定深度SBWcc可以走多少个链接的限制-这限制了事物可以获得多少控制。
流程推荐人检查
许多网站正在使用一种称为“引荐来源标头”的东西来检查下载的有效性。这样做是为了确保您在未查看整个页面(其中可能包含广告和其他垃圾)的情况下,不会从网站请求单个图像。
例如,假设您正在查看网页“ www.website.com/page1.html”,并且其中包含您希望SBWcc下拉的图像“ www.website.com/image1.gif”。
在普通网站上,您可以在SBWcc中输入“ www.website.com/image1.gif”的URL,然后下载。但是,如果您在引荐来源网址审核过的网站上输入www.website.com/'image1.gif',则可能会弹出某种“无效请求”或“未经授权的请求”图像...
解决方案是在SBWcc的高级设置中使用“初始引荐来源标头”设置。要到达那里,请单击“设置”选项卡,然后单击“常规”选项卡,最后单击“高级”按钮。这将弹出“高级设置”对话框。我们在这里感兴趣的是“初始引荐来源标头”。
在初始引荐来源标头框中,您需要输入包含要下载图像的页面的完整URL。在我们的示例中,名称可能是“ www.website.com/page1.html”。您的情况会有所不同。
支持认证/密码站点
许多网站都要求输入密码才能访问。 SBWcc旨在支持从这些站点下载。您将需要在SBWcc身份验证设置中输入正确的密码信息。身份验证位于身份验证选项卡下,并包括所需数量的站点/ URL设置。
按<添加>按钮添加新的身份验证设置。系统将提示您输入以下内容:
主机/ URL子字符串。这是一个文本字符串,用于唯一标识将应用身份验证的URL。例如,如果您要访问的站点是“ www.mysite.com”,则只需在框中输入主机名“ www.mysite.com”。某些站点可能对不同部分具有多个身份验证。例如,您可以为“ www.mysite.com/section1/”和“ www.mysite.com/section2/”设置密码。
。在这种情况下,只需输入较长的url字符串即可区分它们。一个很好的技巧是使主机名/ URL子字符串尽可能短,以唯一地标识经过身份验证的页面。如果可以使用简单的主机名(例如“ www.mysite.com”),请使用它。没有理由花哨。
验证“用户名”。这是站点管理员分配给您的身份验证用户名。
身份验证“密码”。这是站点管理员分配给您的密码。
AdultCheck网站:
许多人要求我提供有关如何访问经过AdultCheck验证系统保护的网站的信息,这与传统的Web身份验证不同。 AdultCheck验证系统的工作原理如下
要求用户输入他/她的AdultCheck密钥
按下提交按钮后,密钥将发送到AdultCheck网站进行验证
如果密钥正确,则将用户的浏览器重定向到原始系统上的网页(付费区域)
主要观察到的是,浏览器在步骤3中指向的URL通常不受保护。要从受保护的站点下载URL,您需要将其输入SBWcc。通常,URL将由浏览器显示在浏览器窗口顶部附近。但是,情况并非总是如此,带有“框架”的案例站点通常会向您隐藏确的URL,因此您可能需要进行一些调查。
我的目的不是为您提供访问该网站的具体说明,而是一个很好的提醒是使用您的br
您可以正常访问该网站,确定付款区域的URL,然后将该URL输入SBWcc。
筛选项
SBWcc具有多个内置过滤选项。它们都位于“过滤器”标签下。首先是一盒下载文件类型。这些类型表示Internet Mime内容类型,并且与文件扩展名松散相关(即,Text / Html = .html,.htm和Image / Jpeg = .jpeg,.jpe,.jpg等)。取消选中文件类型将阻止这些文件下载到您的硬盘驱动器。
第二种过滤方法是按文件大小。您可以设置最小和最大文件大小。
应该注意的是,在Spider(或Page)模式下,SBWcc必须始终下载HTML文件。这是因为HTML文件包含蜘蛛爬行所需的超链接。因此,筛选选项不会阻止HTML文件的下载。 (取消选中“文本/ HTML”文件类型将阻止保存HTML文件,但不会传输HTML文件)

 POCO美女秀 1.0.2安卓版
POCO美女秀 1.0.2安卓版 POCO照片 1.2.2安卓版
POCO照片 1.2.2安卓版 POCO美食相机 1.5.4安卓版
POCO美食相机 1.5.4安卓版 POCO摄影 1.0.3安卓版
POCO摄影 1.0.3安卓版 POCO亲子相机 1.6.3安卓版
POCO亲子相机 1.6.3安卓版 POCO相机 2.2.2安卓版
POCO相机 2.2.2安卓版 POCO美人相机 2.2.2安卓版
POCO美人相机 2.2.2安卓版 简拼 1.1.3安卓版
简拼 1.1.3安卓版 印象 1.0.1安卓版
印象 1.0.1安卓版 flareget是一款功能非常强大的下载工具.flareget 破解版支持下载各类网游、影视资源等,在下载的同时还提高了下载速度和限制网速.本站提供flareget下载,有需要的朋友快来下载吧!
介绍:
flareget是一款方便实用的下载...
flareget是一款功能非常强大的下载工具.flareget 破解版支持下载各类网游、影视资源等,在下载的同时还提高了下载速度和限制网速.本站提供flareget下载,有需要的朋友快来下载吧!
介绍:
flareget是一款方便实用的下载...  啄木鸟相册下载器是一款可批量下载又拍图片管家、花瓣画板、又拍社区相册、QQ空间(公开/好友/问题)、QQ群、腾讯微博、淘宝(整店/分类/单品)、天猫(整店/分类/单品)、天猫超市单品、阿里公司相册、阿里产品图片(...
啄木鸟相册下载器是一款可批量下载又拍图片管家、花瓣画板、又拍社区相册、QQ空间(公开/好友/问题)、QQ群、腾讯微博、淘宝(整店/分类/单品)、天猫(整店/分类/单品)、天猫超市单品、阿里公司相册、阿里产品图片(...  领航QQ群文件批量下载工具是一款值得拥有的QQ群共享文件批量下载工具,软件方便简单,自带使用方法,能够帮助用户秒下载共享文件,需要的话可以来下载使用。
功能:
Q群文件搬砖神器,秒拿群内资源。
功能简单,上手容...
领航QQ群文件批量下载工具是一款值得拥有的QQ群共享文件批量下载工具,软件方便简单,自带使用方法,能够帮助用户秒下载共享文件,需要的话可以来下载使用。
功能:
Q群文件搬砖神器,秒拿群内资源。
功能简单,上手容...  BT资源宝盒(全网搜索各种种子软件)是一款小编专门为喜欢在网上搜索各种种子的朋友们找到的一款快速搜索全网种子的强大软件。而且用户直接输入种子打开即可播放,不需要下载和缓冲哦。BT资源宝盒为用户提供精准的检索引...
BT资源宝盒(全网搜索各种种子软件)是一款小编专门为喜欢在网上搜索各种种子的朋友们找到的一款快速搜索全网种子的强大软件。而且用户直接输入种子打开即可播放,不需要下载和缓冲哦。BT资源宝盒为用户提供精准的检索引...  豆丁种子搜索器是一款磁力链接、迅雷链接、BT种子文件搜索工具,可以一键将搜索到的磁力链接保存至百度云盘,同时具备磁力链接转BT种子文件功能,保证单个资源的下载成功率。
更新日志:
1、增加磁力链接转种子文件...
豆丁种子搜索器是一款磁力链接、迅雷链接、BT种子文件搜索工具,可以一键将搜索到的磁力链接保存至百度云盘,同时具备磁力链接转BT种子文件功能,保证单个资源的下载成功率。
更新日志:
1、增加磁力链接转种子文件...  QQ2017
QQ2017 微信电脑版
微信电脑版 阿里旺旺
阿里旺旺 搜狗拼音
搜狗拼音 百度拼音
百度拼音 极品五笔
极品五笔 百度杀毒
百度杀毒 360杀毒
360杀毒 360安全卫士
360安全卫士 谷歌浏览器
谷歌浏览器 360浏览器
360浏览器 搜狗浏览器
搜狗浏览器 迅雷9
迅雷9 IDM下载器
IDM下载器 维棠flv
维棠flv 微软运行库
微软运行库 Winrar压缩
Winrar压缩 驱动精灵
驱动精灵