




ucinet是一款非常好用的社会网络分析工具。社会网络分析就来使用ucinet。该软件提供了多种数据分析,您可以选择矩阵,边距固定的矩阵,边距固定的矩阵,测量社会学,伯努利分布,多项式分布,Erdos-Renyi-随机图,添加相关信息数据到软件中进行分析。软件顶部显示很多功能,用户可以单击相关的可视化功能来处理数据,或者选择网络功能来分析数据,软件相关的功能有附加功能帮助提示,在加载中您可以在分析数据和数据时查看帮助。编辑器提供的安装程序包有两个版本,一个是正式的英文版本,带有详细的帮助内容,另一个是显示中文界面的绿色版本,但没有帮助内容。用户可以根据需要打开相应的版本!
使用说明:
1.打开ucinet并提示已注册软件。如果可以使用此软件,请开始工作。
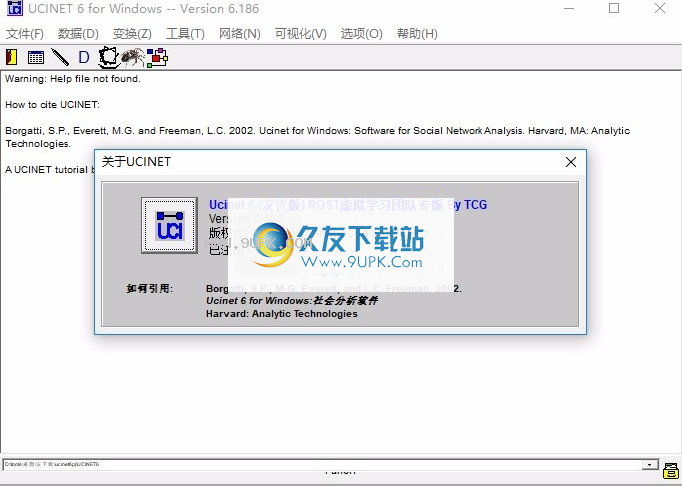
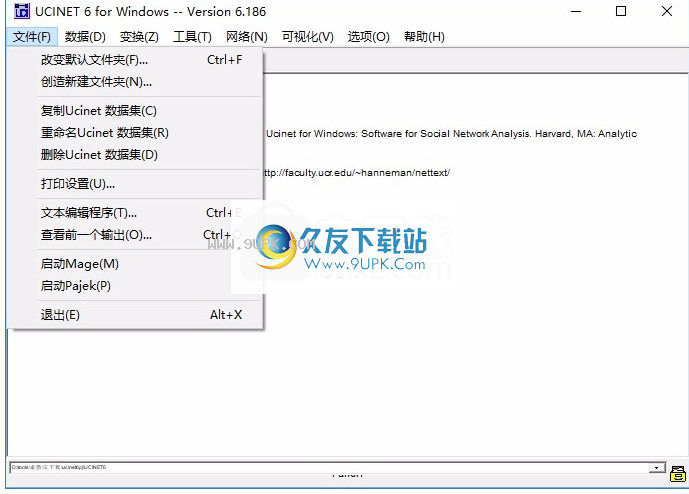
2.这是文件菜单界面,它支持更改默认文件夹,创建新文件夹以及复制Ucinet数据集。
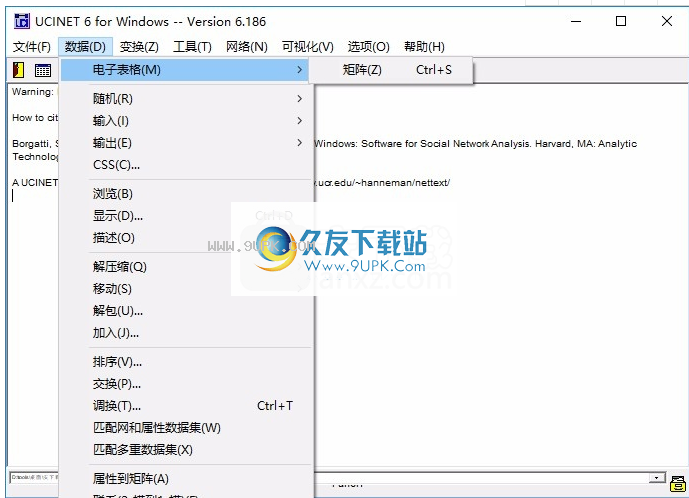
3.数据添加功能,加载您需要在软件中使用的数据,可以添加电子表格数据
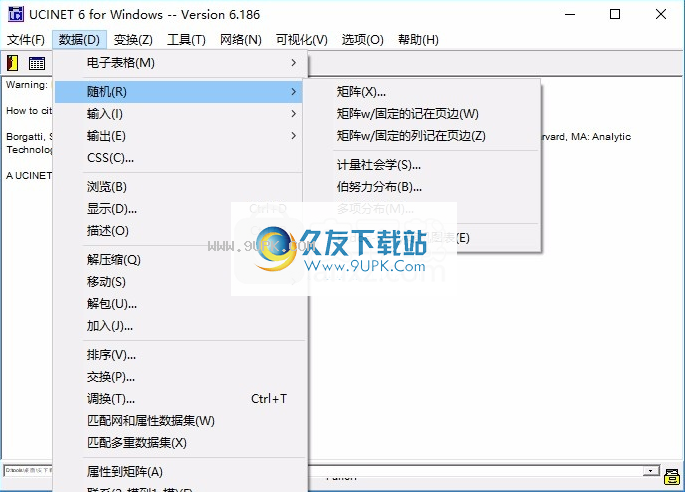
4.可以选择矩阵数据,可以选择测量社会学,劳动分布,多项分布
5.如图所示,它提示您设置随机矩阵数据,并在软件中输入特定的数据内容
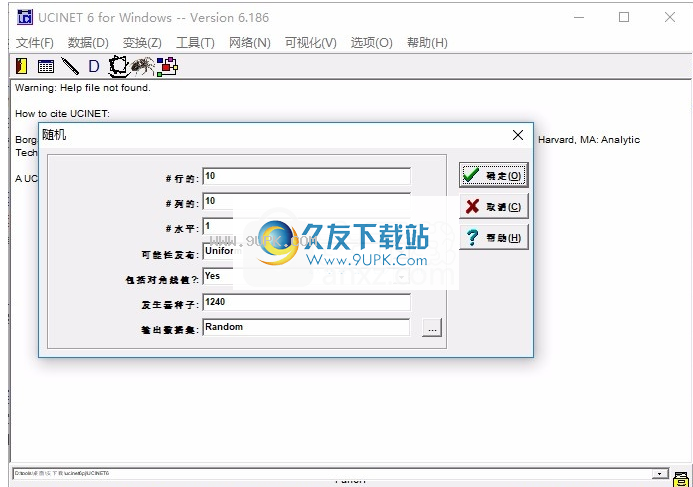
6.单击“确定”进入数据编辑界面,下面是生成的数据

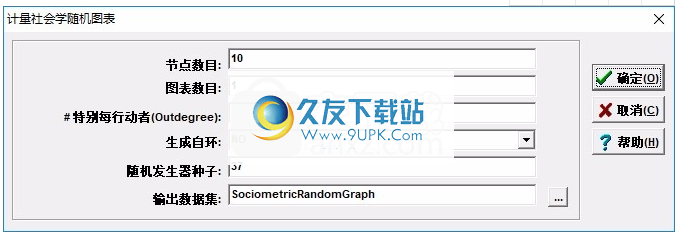
7.测量社会学分析界面,在软件中设置节点数,图数,特殊角色数(Outdegree),自生成循环,随机生成种子和输出数据集
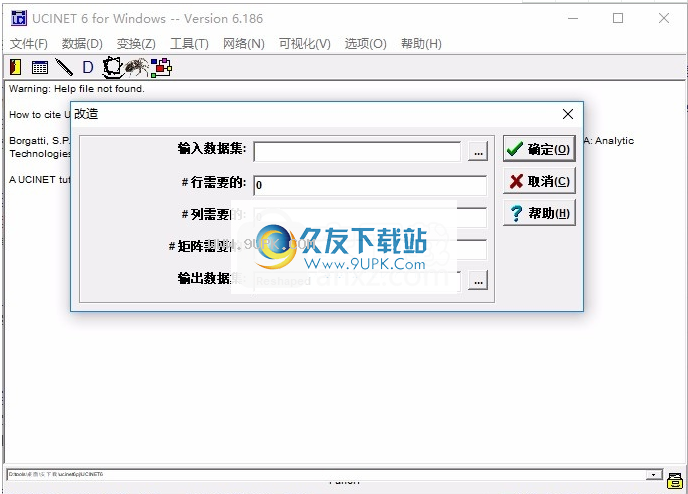
8.变形数据分析,输入数据集,行需求,列需求,矩阵需求,输出数据集
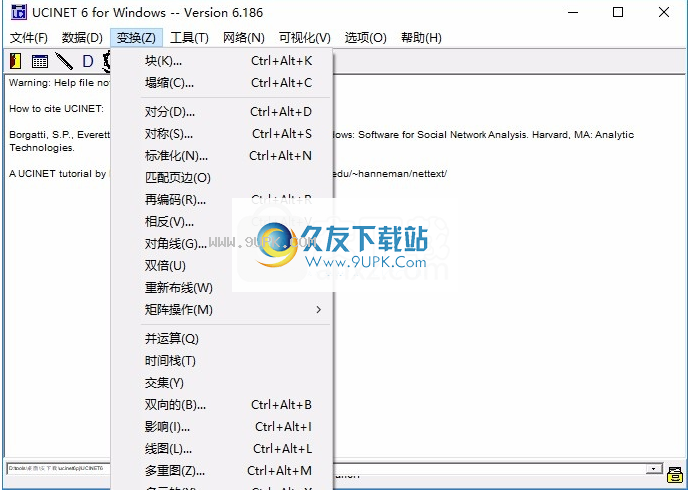
9.转换功能,支持分块,折叠,对分,对称,标准化,匹配余量和重新编码
10.矩阵运算功能,支持内部数据集和中间数据集
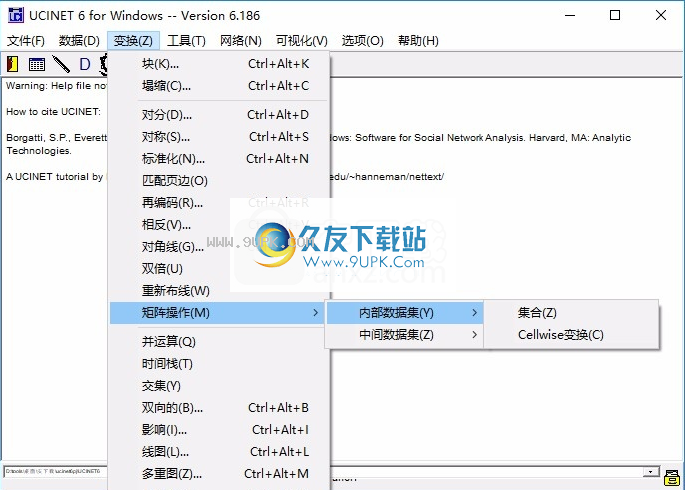
11.2种模式缩放:SVD,因子分析,对应,还可以选择一致性分析

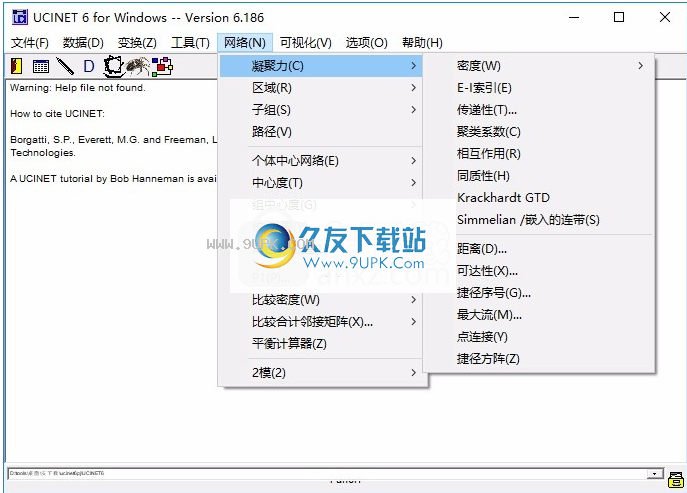
12.内聚力:密度,E指数,传递性,聚类系数,相互作用,均匀性(H)
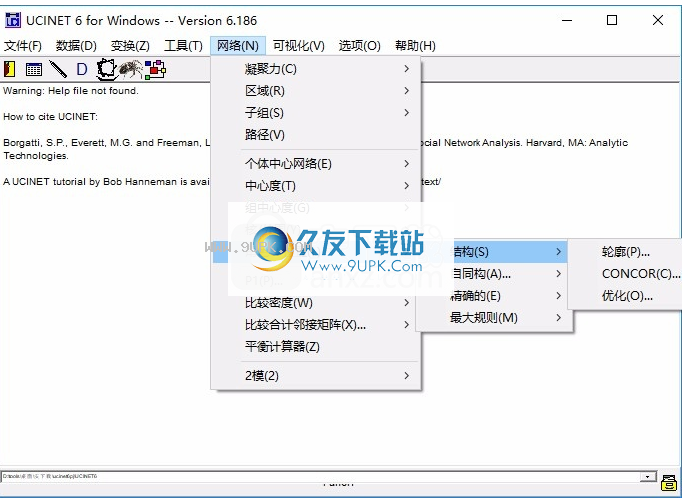
13,结构(S),自同构(A),精确(E),最大规则(M)
软件功能:
1.ucinet可以处理很多数据,可以处理电子表格上的数据
2.表数据可以在矩阵中扩展,并且可以在矩阵界面中分析数据
3.支持多种数据图显示,可以查看,散点图,直方图,树形图
4.提供多种矩阵数据处理,您可以选择要记录在边距中的矩阵w / fixed,要记录在边距中的矩阵w / fixed列
5.还支持随机数据统计,并且可以选择定量社会学分析
6.它还支持Burst Effort分布,多重分布,Erdos-RenyiB随机图
7.支持多种输入方式,支持可以选择DL,多个DL文件,VNA,Pajek
8. Krack图形,Negopy,RAW,ExcelR矩阵也可以在输入界面中找到
9.支持将数据输出到DL,Krack绘图,Mage,Pajek,Metis,RAW,Excel
10.您也可以在软件中查看CSS数据以提供详细的配置
官方教程:
简介:社交网络数据有何不同?
一方面,社交网络数据确实没有异常。社交网络分析师确实使用一种专门的语言来描述他们使用的观察集的结构和内容。但是,您也可以使用更熟悉的方法(例如横断面调查研究)来描述和理解网络数据。
另一方面,由社交网络分析师开发的数据集通常看起来与调查研究人员和统计分析师所熟悉的传统矩形数据阵列完全不同。这些差异非常重要,因为它们使我们以不同的方式看待数据,甚至导致对如何应用统计数据有不同的看法。
“常规”社会科学数据由矩形测量数组组成。数组的行是案例,主题或观察值。列由属性,变量或度量的分数(定量或定性)组成。一个简单的例子如图1.1所示。然后,数组的每个单元将描述某个演员(行)在某个属性(列)上的得分。在某些情况下,这些阵列可能具有第三维,代表观察面板或多个组。
图1.1。矩形数据数组的示例

基本数据
结构允许我们比较各种属性之间的参与者之间的相似性或不相似性(通过比较行)。或者,也许更常见的是,我们检查各个参与者之间变量分布的相似度或不相似度(通过比较或相关列)。
“网络”数据(以其最纯粹的形式)由测量的方阵组成。数组的行是案例,主题或观察值。数组的列是-并注意与常规数据的主要区别-一组相同的案例,主题或观察结果。参与者之间的关系在数组的每个单元格中描述。图1.2显示了一个简单的示例,该示例描述了四个人之间的友谊网络。
图1.2。网络数据方阵示例

我们可以以与属性数据相同的方式查看此数据结构。通过比较数组的行,我们可以看到哪些参与者与他们选择的其他参与者相似。通过查看这些列,我们可以看到在被他人选中方面,谁与谁相似。这些是查看数据的有用方法,因为它们可以帮助我们查看哪些参与者在网络中处于相似位置。这是网络分析的第一个主要重点:查看参与者如何在整个网络中定位或“嵌入”。
但是网络分析人员也可能从第二个角度(即整体视图)来看数据结构。分析人员可能会注意到矩阵中的1和0近似相等。这表明总体上存在中等的“密度”。分析人员还可以比较对角线上方和下方的单元格,以查看选择中是否存在等价关系(例如,鲍勃选择了泰德,泰德选择了鲍勃吗?)。这是网络分析的第二个主要重点:了解个人选择的整体模式如何导致整体模式。
可以用与“常规数据”相同的术语来考虑网络数据集。您可以将行视为案例列表,将列视为每个参与者的属性(也就是说,您可以将与其他参与者的关系视为每个参与者的“属性”)。实际上,网络分析师使用的许多技术(例如计算相关性和距离都以与传统数据完全相同的方式应用于网络数据。
尽管可以将网络数据描述为常规数据的一种特殊形式(的确如此),但是网络分析人员以完全不同的方式查看数据。网络分析人员没有考虑参与者与其他参与者之间的关系如何描述“自我”的属性,而是看到了嵌入参与者中的连接结构。通过关系而不是属性来描述参与者。而且,关系本身与他们联系的参与者一样重要。
常规数据和网络数据之间的主要区别在于,常规数据侧重于参与者和属性。网络数据侧重于参与者和关系。研究人员在决定研究设计,抽样,开发测量结果和处理结果数据时必须做出的选择可能会导致重点不同。网络分析师使用的研究工具与其他社会科学家的研究工具没有区别(在大多数情况下没有区别)。但是网络研究的特殊目的和重点确实需要不同的考虑。
在本章中,我们将研究在社交网络分析的设计,采样和度量中出现的一些问题。我们的讨论将集中在网络数据的两个部分:节点(或参与者)和边缘(或关系)。我们将尝试使用属性数据来说明网络数据与更熟悉的参与者之间的异同。我们将引入一些新术语,这些术语使描述网络数据的特殊功能更加容易。最后,我们将简要讨论如何为统计工具的应用生成网络数据和参与者属性数据之间的差异。
节点数
网络数据由参与者和关系(或“节点”和“边缘”)定义。网络数据的节点或参与者部分似乎很简单。社会科学中的其他经验方法也从案例,主题或样本要素的角度进行思考。但是,大多数网络数据具有一个差异,即通常如何收集此类数据以及所研究的样本和种群类型非常不同。
网络分析关注的是参与者之间的关系,而不是单个参与者及其属性。这意味着,与许多其他类型的研究(最常见的调查)一样,参与者不是独立采样的。例如,假设我们正在研究友谊关系。约翰已被选为我们的样本。当我们问他时,约翰确定了七个朋友。我们需要追踪
k这七个朋友中的每一个,并向他们询问他们的友谊纽带。 这七个朋友在我们的示例中,因为John是(反之亦然),因此“示例元素”不再“独立”。
非网络研究中包含的节点或参与者通常是独立概率采样的结果。 网络研究更可能将某个(通常是自然发生的)边界内的所有参与者包括在内。 至少在传统意义上,网络研究通常根本不使用“样本”。 相反,他们倾向于包括特定人群中的所有参与者。 当然,网络研究中包括的人群可能是一些较大人群的样本。 例如,当我们研究学生在课堂上的互动方式时,我们将课堂中的所有孩子都包括在内(也就是说,我们在课堂上研究了整个人口)
。但是,教室本身可以通过概率方法从一组教室(例如,学校中的所有教室)中选择。
在(许多)网络研究中,总人口被用作选择观察值的一种方式。对于分析人员来说,明确分析每个人口的界限以及如何在该人口中选择单个观察单位对于分析人员而言非常重要。网络数据集通常涉及多个分析级别,并且参与者被嵌入到最低级别(也就是说,“嵌套”设计的语言可用于描述网络设计)。
人口,样本和边界
社交网络分析师很少在工作中抽样。最常见的是,网络分析人员将识别一些人口并进行普查(即,将人口的所有要素都包括在内作为观察单位)。网络分析人员可以检查文本中出现的所有名词和对象,生日聚会上的每个人,组织的所有成员,社会阶层的邻居或亲戚(例如某个地区的房东或王室成员)。
调查研究方法通常使用完全不同的方法来确定要研究的节点。所有节点的列表(有时是分层的或群集的),并且通过概率方法选择单个元素。从某种意义上说,每个人都可以彼此互换,这种方法的逻辑就是将每个人视为一个单独的“副本”。
由于网络方法侧重于参与者之间的关系,因此不可能独立地对参与者进行抽样以将其包括为观察值。如果某个演员恰好被选中,那么我们还必须包括与我们有(或可能有)联系的所有其他演员。结果,网络方法倾向于通过普查而不是样本来研究整个人口(我们将在抽样连接的主题下不久讨论许多例外情况)。
网络分析师所研究的人非常不同。在一种极端情况下,它们可能由文本中的符号或语音中的声音组成;在另一个极端,世界国家体系中的国家可能构成节点总数。当然,也许最常见的是个人。但是,在每种情况下,要研究的整体要素都在一定范围内。
网络分析师研究了两个主要的人口边界。可能最常见的边界是演员自己施加或创建的边界。教室,组织,俱乐部,邻里或社区的所有成员可以形成一个整体。这些是自然发生的集群或网络。因此,从某种意义上说,社交网络研究通常在已知人群周围划定界线,这是先验的并成为网络。或者,网络分析人员可能会使用更多的“人口统计”或“生态学”方法来定义人口边界。我们可以通过联系在有限空间区域内符合条件或满足某些条件(家庭总收入每年超过1,000,000美元)的所有人员来进行观察。在这里,我们可能有理由怀疑互联网的存在,但是研究的实体是调查人员强加的抽象集合,而不是参与者已经识别和标记的制度化社会行为模式。
网络分析师可以通过复制人口来扩大研究范围。与其研究一个区块,不如研究几个区块。可以通过比较总体和检验假设来复制这种类型的设计(您可以使用抽样方法选择总体)。网络研究扩展其范围的第二种同样重要的方法是通过包括多个级别的分析或模型。
软件特色:
1,HUBBEL / KATZ(影响)
目的:使用Hubbell,Katz或Taylor的模型来计算每对顶点之间的影响度量。
描述:矩阵的连续幂提供了一种影响力的度量,因为它们列举了所有节点对之间给定长度的可能步长的数量。由于假定较长的步行路程对冲击的影响较小,因此应包括衰减因子,并应考虑所有步行路程的总和。 Hubbell在系列中包括身份矩阵,而Katz不包括。
对于Hubbell,影响矩阵为I + S(bA)^ i,在特定条件下等于(I-bA)的逆。因此,在相同条件下,对于Katz,影响矩阵是(I-bA)-I的逆矩阵。 Taylor度量是Katz度量的规范化版本。对于系列中的每个幂,请从行边距中减去列边距,然后通过该长度的总步数进行归一化。
2,网络>中心>关闭
目的:计算每个顶点的距离和标准化的邻近中心度,并给出整个网络的邻近中心度。
描述:顶点的距离是测地线和其他顶点的长度之和。距离的倒数是距离的中心。顶点的标准化贴近度是贴近度的倒数除以表示为百分比的最小可能贴近度。作为在总和之后求倒数的替代方法,您可以在总和之前倒数。在这种情况下,接近度是往复距离的总和,因此无限距离的贡献值为零。也可以通过除以最大值进行归一化。另外,该例程还允许用户测量通过所有路径的距离或所有路径的长度之和。如果指示数据,则例程将为短距离和长距离计算单独的度量。
3.网络>角色和位置>结构对等> CONCOR
目的:基于迭代相关收敛(CONCOR),通过划分块对网络数据进行分区。
描述:给定一个邻接矩阵或一组用于不同关系的邻接矩阵,可以通过以下过程来形成相关矩阵。通过在每个邻接矩阵中合并第i行,形成顶点i的轮廓矢量;相关矩阵的第i个,第j个元素是i和j的轮廓向量的Pearson相关系数。这个(方形,对称)矩阵称为第一相关矩阵。
该过程可以在相关矩阵上迭代执行,直到收敛为止。现在每个条目是1或-1。该矩阵用于将数据分为两个块,以使同一块的成员呈正相关,而不同块的成员呈负相关。
4,数据>联接
目的:从成员数据创建网络。
说明:转换t
通过使用两种不同类型的二进制乘法来形成A''或A'A,从而将m´n矩阵转换为m´m或n´n。给定二元关联矩阵A,其中行代表参与者,列为事件,矩阵A'给出参与者同时参与的事件数量。因此,AA'(i,j)是演员i和演员j都参加的活动的数量。矩阵A'A给出了一对演员同时参与的活动数量。因此,A'A(i,j)是参与事件i和事件j的演员人数。如果数据有价值,则有两种选择。叉积(或同现法)可构造类似于二进制情况的标准矩阵乘积。最小值方法使用两个值中的最小值代替产品。因此,如果第i行为(5,6,0,1),第j行为(4,2,4,0),则AA'(i,j)为5 * 4 + 6 * 2 + 0 * 4 +1 *对于叉积,0 = 32;对于最小方法,min(5,4)+ min(6,2)+ min(0,4)+ min(1,0)= 6。这些对于二进制数据产生相同的答案。
该例程还允许对最终矩阵进行归一化以适应不同大小的事件。考虑两个参与者i和j,让X为他们都参加的活动数量和他们未参加的活动数量的乘积,让Y为我参加的活动数量和数量的乘积。 j没有参加的活动。我参加了,但是我没有参加。如果X = Y,则归一化的条目为0.5,否则为(X-SQRT(XY))/(X-Y)。

 旅游攻略网
旅游攻略网 鸵鸟旅行网
鸵鸟旅行网 来来旅行
来来旅行 途牛旅游
途牛旅游 票付通
票付通 途牛精选
途牛精选 同程旅行
同程旅行 携程旅行app
携程旅行app 飞猪购票
飞猪购票 神奇旅行
神奇旅行 去哪儿旅行网手机版
去哪儿旅行网手机版 美团
美团 TimePanic日程管理工具 专门用于跟踪你的时间,设置日程任务,自动监控和管理任务,可以记录你每天都干了什么,找出时间都浪费在哪里以利改进。有需要的小伙伴千万不能错过哦~
TimePanic日程管理工具 专门用于跟踪你的时间,设置日程任务,自动监控和管理任务,可以记录你每天都干了什么,找出时间都浪费在哪里以利改进。有需要的小伙伴千万不能错过哦~  Zero Install软件管理器内置了丰富的软件资源,并且可以实现一键安装操作,可以帮你在电脑中安装各种常用的电脑软件,并且支持升级和卸载功能。喜欢可以来久友下载站下载~
Zero Install软件管理器内置了丰富的软件资源,并且可以实现一键安装操作,可以帮你在电脑中安装各种常用的电脑软件,并且支持升级和卸载功能。喜欢可以来久友下载站下载~  通过快手粉丝查粉软件,用户只需要输入快手ID即可完成查粉的目的,现在你不需要打开快手,也能够通过快手粉丝查粉软件时时查看粉丝数量了!
通过快手粉丝查粉软件,用户只需要输入快手ID即可完成查粉的目的,现在你不需要打开快手,也能够通过快手粉丝查粉软件时时查看粉丝数量了!  优帮资产运维系统能够快速帮助企业创建线下IT客服工单管理,系统对企业资产进行数据标准化的管理,通过扫描二维码创建工单的方式,对线下客服的日常工作进行工单的记录、评价,帮助企业统计分析客服的工作量,随时了解...
优帮资产运维系统能够快速帮助企业创建线下IT客服工单管理,系统对企业资产进行数据标准化的管理,通过扫描二维码创建工单的方式,对线下客服的日常工作进行工单的记录、评价,帮助企业统计分析客服的工作量,随时了解...  用户可以用Viewurl来查看电脑的上网历史记录、访问文件和网址等痕迹,有这方面需要的朋友可以来久友下载站下载试试。
用户可以用Viewurl来查看电脑的上网历史记录、访问文件和网址等痕迹,有这方面需要的朋友可以来久友下载站下载试试。  QQ2017
QQ2017 微信电脑版
微信电脑版 阿里旺旺
阿里旺旺 搜狗拼音
搜狗拼音 百度拼音
百度拼音 极品五笔
极品五笔 百度杀毒
百度杀毒 360杀毒
360杀毒 360安全卫士
360安全卫士 谷歌浏览器
谷歌浏览器 360浏览器
360浏览器 搜狗浏览器
搜狗浏览器 迅雷9
迅雷9 IDM下载器
IDM下载器 维棠flv
维棠flv 微软运行库
微软运行库 Winrar压缩
Winrar压缩 驱动精灵
驱动精灵