


![Allround Automations PL/SQL Developer[数据库软件] 11.0.4.1774 绿色最新版](http://pic.9upk.com/soft/UploadPic/2015-9/20159416131453597.gif)
![Adminers[MySQL管理工具] 1.1.2 中文绿色版](http://pic.9upk.com/soft/UploadPic/2015-9/201592214512270439.jpg)
Apache Superset是一款专业的开源可视化平台。数据库可视化开发软件中的佼佼者Apache Superset。您可以使用此软件在图表上显示数据以进行分析,从而允许用户快速可视化复杂数据并提供分析数据的帮助。您可以使用数据可视化数组浏览数据并通过交互式仪表板查看任何数据。该软件提供了丰富的仪器内容,可以显示不同的数据图,可以自定义图类型,可以使用SQL Lab编写查询来探索数据,并支持大多数常见的数据库,包括MySQL,SQL Server和SQLite,以满足需求用户的视觉数据库需求;超集具有许多功能。导入相关数据可以创建图表和仪表板以执行视觉设计。如果需要,请下载!
官方教程:
创建您的第一个仪表板
本节重点介绍将使用Superset进行数据分析和探索工作流的最终用户的文档(数据分析师,业务分析师,数据科学家等)。
本教程针对想要在Superset中创建图表和仪表盘的人员。我们将向您展示如何将Superset连接到新数据库,以及如何配置该数据库中的表以进行分析。您还将浏览公共数据并将可视化效果添加到仪表板,以了解端到端用户体验。
连接到新数据库
Superet本身没有存储层来存储数据,但是与现有的类似SQL的数据库或数据存储配对。
首先,我们需要将连接凭据添加到您的数据库中,以便可以查询和可视化其中的数据。如果您是通过Docker compose在本地使用Superset,则可以跳过此步骤,因为Postgres数据库(命名示例)已经包含在Superset中,并且已经预先安装了。
为您量身定做。
在“数据”菜单下,选择“数据库”选项:

接下来,单击右上角的绿色+数据库按钮:

您可以在此窗口中配置许多高级选项,但是对于本演练,只需指定两件事(数据库名称和SQLAlchemy URI):
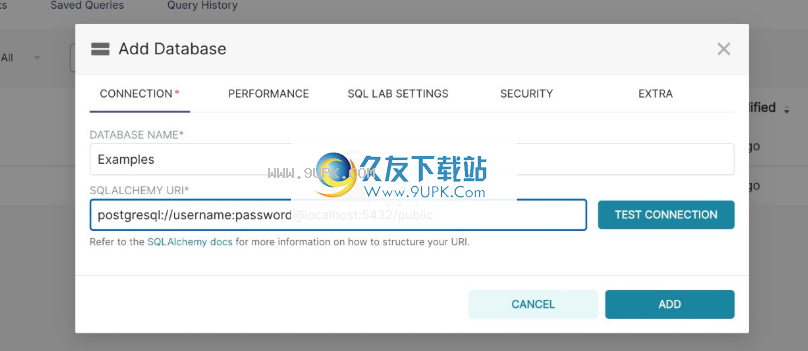
如URI下方的文本所述,您应该参考SQLAlchemy文档为目标数据库创建一个新的连接URI。
单击“测试连接”按钮,以确认一切正常。如果连接看起来不错,请通过单击模态窗口右下角的“添加”按钮来保存配置:
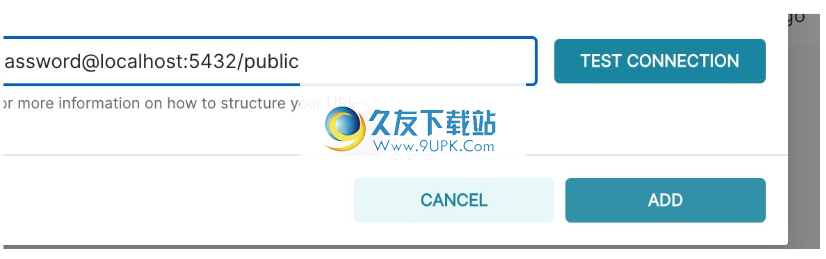
恭喜,您刚刚在Superset中添加了新的数据源!
注册新表格
现在,您已经配置了数据源,您可以选择要在Superset中公开以供查询的特定表(在Superset中称为数据集)。
导航至“数据”→“数据集”,然后选择右上角的+“数据集”按钮。
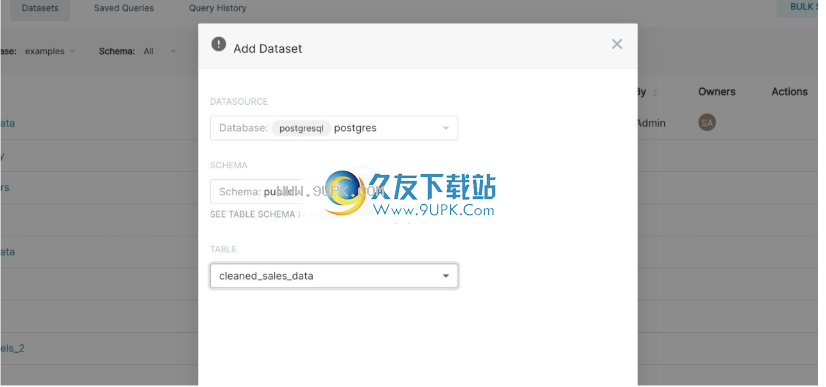
一个模态窗口应该在您面前弹出。使用显示的下拉列表选择数据库,架构和表。在以下示例中,我们从示例数据库中注册了cleaned_sales_data表。
要完成操作,请单击右下角的“添加”按钮。现在,您应该在数据集列表中看到您的数据集。
自定义列属性
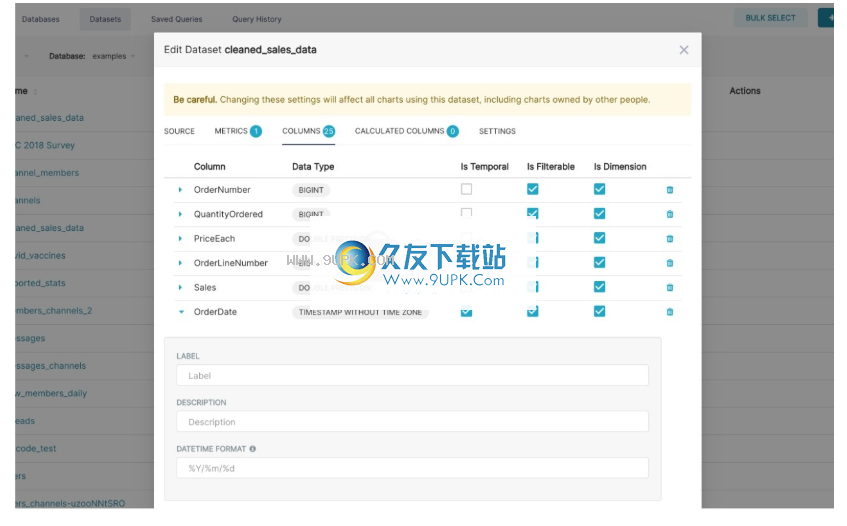
现在,您已经注册了数据集,您可以配置列属性以了解应如何在“浏览”工作流程中处理列:
栏是临时的吗? (是否应将其用于时序图中的切片和切块?)
柱子应该可过滤吗?
列是维吗?
如果它是日期时间列,那么Superset应该如何解析日期时间格式? (使用ISO-8601字符串模式)
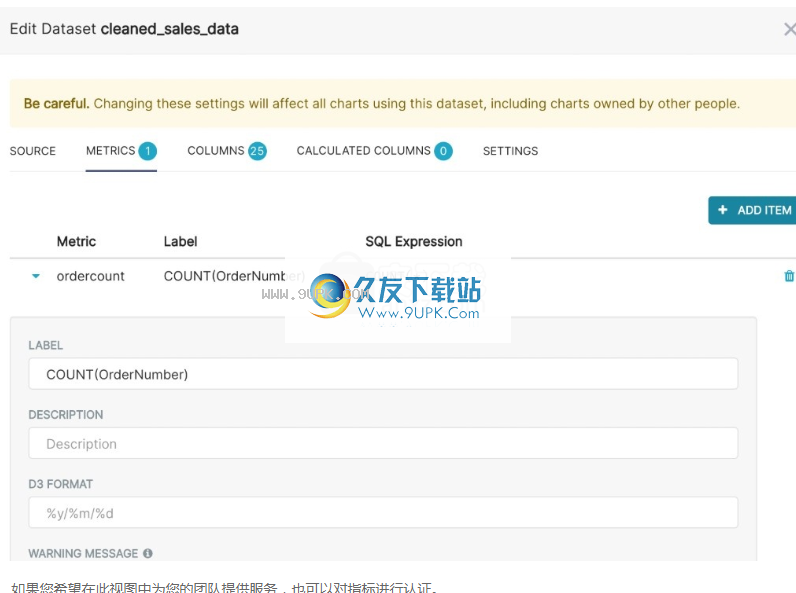
超集语义层
Superset具有较薄的语义层,可以提高分析人员的生活质量。 Superset语义层可以存储两种类型的计算数据:
1.虚拟指示器:您可以编写SQL查询以汇总多个列(例如SUM(已恢复)/ SUM(已确认))中的值,并将它们用作列(例如recovery_rate)以在Explore中进行可视化。允许并鼓励使用汇总函数作为指标。
如果要在此视图中为团队提供服务,则还可以验证指标。
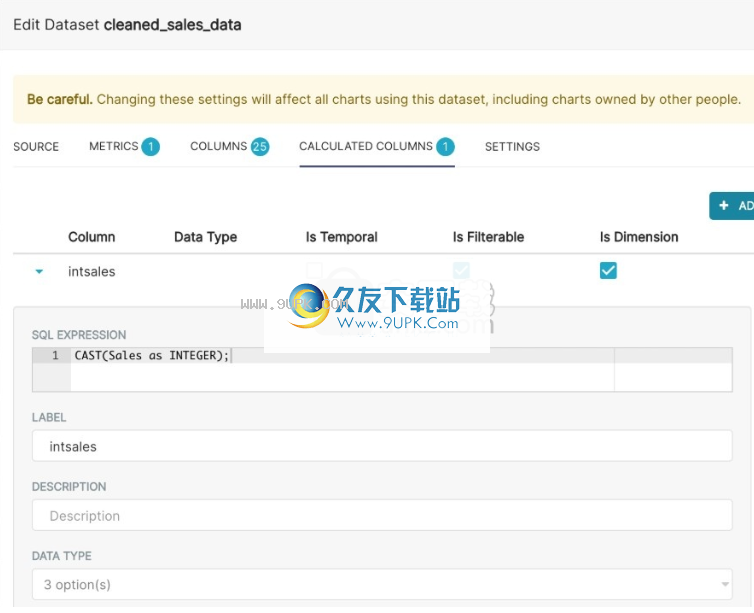
2.虚拟计算列:您可以编写SQL查询来自定义特定列的外观和行为(例如CAST(recovery_rate)为float)。计算列中不允许使用汇总函数。

在“浏览”视图中创建图表
Superset具有2个用于浏览数据的主要界面:
探索:无代码可视化生成器。选择数据集,选择图表,自定义外观,然后发布。
SQL实验室用于清理,联接和准备“探索”工作流的数据的SQL IDE
现在,我们将重点介绍用于创建图表的“浏览”视图。要从“数据集”选项卡启动“探索”工作流,请首先单击将为图表提供动力的数据集的名称。
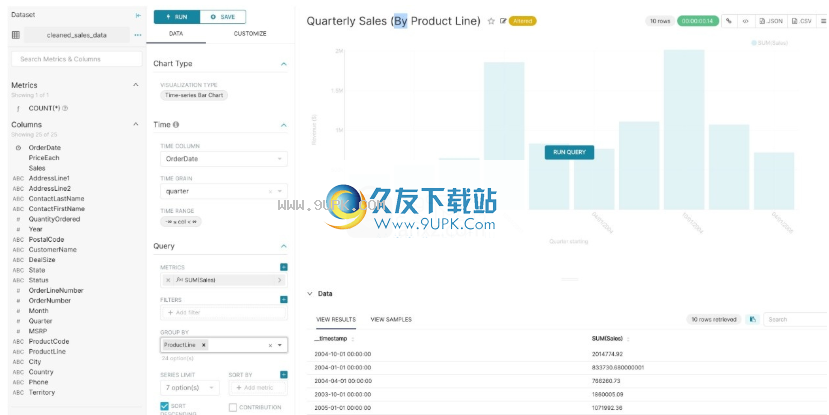
现在,您将获得一个功能强大的工作流,用于浏览数据和在图表上进行迭代。
左侧的“数据集”视图具有列和指示符的列表,并且范围仅限于您选择的当前数据集。
数据图表区域下方的预览还为您提供了有用的数据上下文。
使用“数据”选项卡和“自定义”选项卡,可以更改可视化类型,选择时间列,选择要分组的指标以及自定义图表的外观。
使用下拉菜单自定义图表时,请确保单击“运行”按钮以获取视觉反馈。
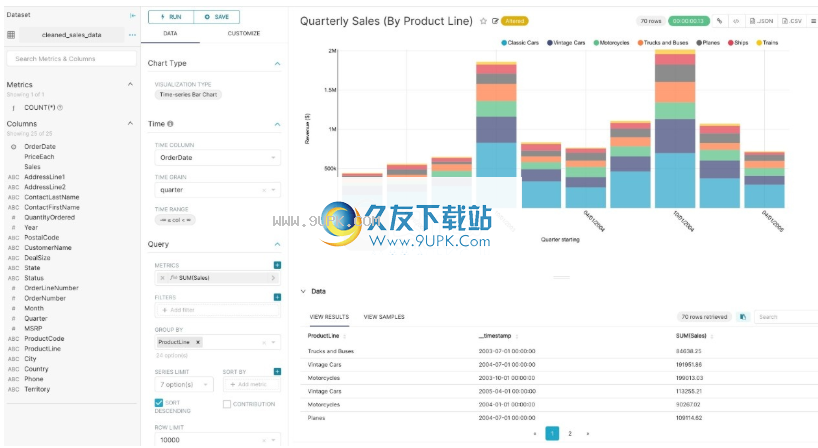
在下面的屏幕截图中,我们可以通过单击下拉菜单中的选项来创建按时间分组的条形图,以按产品系列可视化我们的季度销售数据。
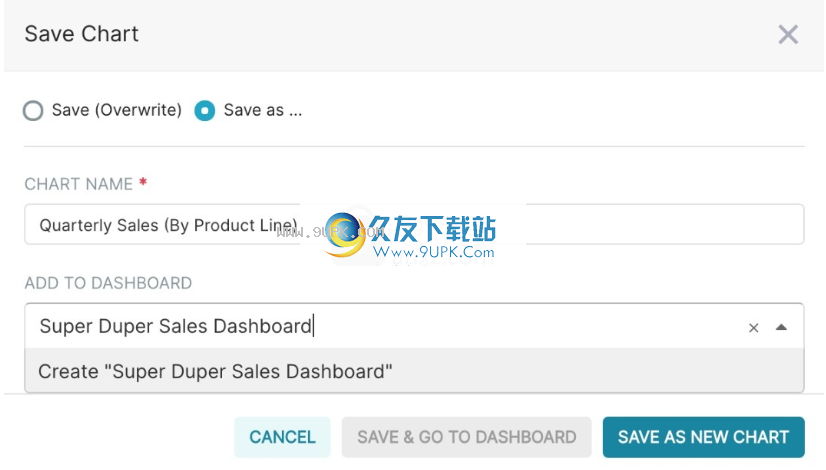
创建切片和仪表板
要保存图表,请首先单击“保存”按钮。你可以:
保存图表并将其添加到现有仪表板
保存图表并将其添加到新的仪表板
在下面的屏幕截图中,我们将图表保存到新的“ Superset Duper销售仪表板”中:

要发布,请单击“保存”并转到仪表板。
在后台,Superset将创建一个切片
并在其压缩数据层中存储创建图表所需的所有信息(查询,图表类型,所选选项,名称等)。

要调整图表大小,请先单击右上角的铅笔按钮。
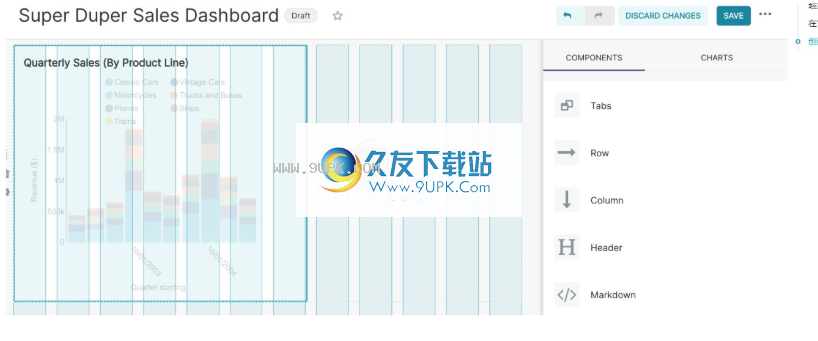
然后,单击并拖动图表的右下角,直到图表布局与所需的基本网格对齐。

单击保存以保存更改。
恭喜你!您已成功链接,分析和可视化了Superset中的数据。还有许多其他表配置和可视化选项,因此开始探索和创建自己的切片和仪表板


常见问题:
1.我可以一次联接/查询多个表吗?
不在“浏览”或“可视化” UI中。 Superset SQLAlchemy数据源只能是单个表或视图。
使用表时,解决方案是创建一个表,其中包含分析所需的所有字段,很可能是通过某些计划的批处理过程完成的。
视图是一个简单的逻辑层,它将任意SQL查询抽象到虚拟表中。这使您可以联接和联合多个表,并对某些转换使用任意的SQL表达式。数据库的性能受到限制,因为Superset会在查询(视图)之上有效地运行查询。一个好的做法可能是限制自己仅将主大表连接到一个或多个小表,并在可能的情况下避免使用GROUP BY,因为Superset会自己执行GROUP BY,并且工作可能会执行两次。降低性能。
无论使用表还是视图,重要的因素是数据库是否足够快以交互方式提供服务,以便在Superset中提供良好的用户体验。
2.我的数据源有多大?
可能很大!超集充当基本数据库或数据引擎之上的薄层。
如上所述,主要标准是数据库是否可以在用户可接受的时间范围内执行查询并返回结果。许多分布式数据库都可以执行以交互方式扫描TB的查询
3.如何向仪表盘添加动态过滤器?
使用“过滤器框”小部件构建切片并将其添加到仪表板。
使用“过滤器框”小部件,您可以定义查询以填充可用于过滤的下拉列表。要构建不同值的列表,我们运行查询,然后根据您提供的指标对结果进行排序,并按降序对其进行排序。
该小部件还具有一个复选框日期过滤器,可以启用仪表板上的时间过滤。选中该框并刷新后,您将看到一个从到的下拉列表
默认情况下,过滤将应用于在共享过滤器所基于的列名称的数据源之上构建的所有片。还需要在表编辑器的“列”选项卡中将列检查为“可过滤”。
但是,如果您不希望在仪表板上过滤某些小部件怎么办?您可以通过以下方式来执行此操作:编辑仪表板,然后编辑表单中的JSON Metadata字段,更具体地说是filter_immune_slices键,该键将接收sliceI
ds数组,该数组不应受到任何仪表板级过滤的影响。
在上述json blob中,切片324、65和92将不受任何仪表板级过滤的影响。
现在记下filter_immune_slice_fields键。这样可以使您更具体,并定义对于特定slice_id应该忽略哪些过滤器字段。
请注意,使用了__time_range关键字,该关键字保留用于处理上述时间边界过滤。
但是,当处理来自不同表或数据库的切片时,过滤会怎样?如果列名是共享的,则将应用过滤器,就这么简单。
4.如何限制仪表板上的定时刷新?
默认情况下,仪表板的常规刷新功能使您可以根据设置的时间表自动重新查询仪表板上的每个切片。但是,有时您不希望刷新所有片,特别是当某些数据移动缓慢或运行繁重的查询时。要从计划的刷新过程中排除特定的片,请将timed_refresh_immune_slices键添加到仪表板JSON元数据字段:
在上面的示例中,如果为仪表板设置了计划的刷新,则将自动按计划查询除324以外的每个切片。
切片刷新也将在指定的时间段内错开。您可以通过将stagger_refresh设置为false来关闭此交织,并通过stagger_time在JSON元数据字段中设置以毫秒为单位的值来修改交织周期:
在这里,如果启用了定期刷新,则整个仪表板将立即刷新。 2.5秒的交织时间将被忽略。
为什么启动时“ flask fab”或超集冻结/挂起/不响应(我的主目录已挂载NFS)?
默认情况下,Superset将创建并使用SQLite数据库〜/ .superset / superset.db。如果在NFS上使用SQLite,则众所周知SQLite不能很好地工作。这是因为NFS上的文件锁定实现已损坏。
您可以使用SUPERSET_HOME环境变量来覆盖此路径。
另一个解决方案是通过在以下位置添加以下内容来更改sqlite数据库的存储位置superset_config.py:
SLALCHEMY_DATABASE_URI ='sqlite://///新/位置/superset.db'
5.如果表结构改变了怎么办?
手表模型在不断发展,Superset需要反映这一点。通常在仪表板的生命周期中添加新的维度或指标。为了让Superset发现新列,所有要做的就是转到菜单->源->表格,单击已更改其架构的表格旁边的编辑图标,然后从“详细信息”选项卡中单击“保存”。 。在幕后,将合并新的列。之后,您可能需要稍后重新编辑该表以配置“列”选项卡,选中相应的框并再次保存。
6.我可以使用哪个数据库引擎作为Superset的后端?
应该注意的是,数据库后端是Superset使用的OLTP数据库,用于存储其内部信息,例如您的用户列表,切片和仪表板定义。
Superset已通过Mysql,Postgresql和Sqlite作为后端进行了测试。建议将Superset安装在这些数据库服务器之一上进行生产。
使用非列存储(例如Vertica,Redshift或Presto(例如非OLTP数据库))作为数据库后端根本无法工作,因为这些数据库不是为此类工作负载设计的。在Oracle,Microsoft SQL Server或其他OLTP数据库上进行安装可能会起作用,但尚未经过测试。
请注意,几乎所有具有SqlAlchemy集成的数据库都可以用作Superset数据源,而不可以用作OLTP后端
软件功能:
超集提供:
直观的界面,用于可视化数据集和制作交互式仪表板
多种精美的可视化显示您的数据
无代码可视化构建器,用于提取和呈现数据集
世界一流的SQL IDE,用于为可视化准备数据,包括丰富的元数据浏览器
轻量级语义层使数据分析人员能够快速定义自定义维度和指标
为大多数说SQL的数据库提供开箱即用的支持
无缝的内存中异步缓存和查询
一种可扩展的安全模型,该模型允许配置有关谁可以访问哪些产品功能和数据集的非常复杂的规则。
与主要的身份验证后端(数据库,OpenID,LDAP,OAuth,REMOTE_USER等)集成
添加自定义可视化插件的功能
用于程序化定制的API
云原生架构,专为扩展而设计
Superset是云原生的,旨在提供高可用性。它被设计为可扩展到大型分布式环境,并且可以在容器中很好地工作。尽管您可以在中等设置下或仅在笔记本电脑上轻松测试Superset驱动器,但扩展平台几乎没有任何限制。
在灵活性方面,Superset还是云原生的。它允许您选择:
Web服务器(Gunicorn,Nginx,Apache),
元数据数据库引擎(MySQL,Postgres,MariaDB等),
消息队列(Redis,RabbitMQ,SQS等),
结果后端(S3,Redis,Memcached等),
缓存层(Memcached,Redis等),
Superset还可以与NewRelic,StatsD和DataDog等服务一起很好地工作,并且可以针对大多数流行的数据库技术运行分析工作负载。
目前,Superset已在许多公司中大规模运营。例如,Superset在Kubernetes的Airbnb生产环境中运行,每天为600多个活跃用户提供服务,每天查看超过100,000个图表。
软件特色:
Superset快速,轻巧,直观,并具有多种选项,因此,各种技能的用户都可以轻松浏览和可视化其数据,从简单的线形图到高度详细的地理空间图。
1,功能强大但易于使用
使用我们简单的无代码可视化构建器或最新的SQL IDE即可快速轻松地集成和浏览数据。

2,与现代数据库集成
Superset可以通过SQLAlchemy连接到任何基于SQL的数据源,包括PB级现代云本机数据库和引擎。

3,现代建筑
Superset轻巧且具有高度可伸缩性,并且可以利用现有数据基础结构的功能,而无需额外的抽象层。

4,丰富的可视化和仪表板
Superset带有各种漂亮的可视化效果。我们的可视化插件架构使将自定义可视化直接构建到Superset中变得容易。


 易车二手车最新版 2016.0319 5.7.2官方安卓版
易车二手车最新版 2016.0319 5.7.2官方安卓版 二手车圈子 4.3.8安卓版
二手车圈子 4.3.8安卓版 厦门二手车 1.0.2安卓版
厦门二手车 1.0.2安卓版 58同城二手车 7.2.2.0最新安卓版
58同城二手车 7.2.2.0最新安卓版 易车二手车 5.9.4安卓版
易车二手车 5.9.4安卓版 全民二手车 1.0安卓版
全民二手车 1.0安卓版 易诚二手车
易诚二手车 商用二手车 1.2.1安卓版
商用二手车 1.2.1安卓版 公平价二手车 3.2.2安卓版
公平价二手车 3.2.2安卓版 小猪二手车网 4.9.0官网安卓版
小猪二手车网 4.9.0官网安卓版 2SC花乡二手车 1.8.6安卓版
2SC花乡二手车 1.8.6安卓版 淘车二手车 1.1安卓版
淘车二手车 1.1安卓版 SQL Operations Studio是一款能够轻松管理数据库的专业软件。编程人员能够使用这款SQL Operations Studio轻松管理数据库。
SQL Operations Studio是一款能够轻松管理数据库的专业软件。编程人员能够使用这款SQL Operations Studio轻松管理数据库。  Fasto No SQL是一款绿色免费的数据库管理工具。数据库管理人员必备数据库管理神器Fasto No SQL。
Fasto No SQL是一款绿色免费的数据库管理工具。数据库管理人员必备数据库管理神器Fasto No SQL。  Address Organizer Deluxe是一款专业的地址数据库管理工具。对于地址数据库的专业管理你一定需要这款功能强大的Address Organizer Deluxe。
Address Organizer Deluxe是一款专业的地址数据库管理工具。对于地址数据库的专业管理你一定需要这款功能强大的Address Organizer Deluxe。  JsonToOracle是一款专业的json导入oracle软件。数据库人员如果需要把json导入oracle可以来试试这款JsonToOracle。
JsonToOracle是一款专业的json导入oracle软件。数据库人员如果需要把json导入oracle可以来试试这款JsonToOracle。  navicat for sql server 12是一款能够轻松进行sql server管理的专业软件。对sql server进行可视化管理这款navicat for sql server 12是一款非常不错的软件。
navicat for sql server 12是一款能够轻松进行sql server管理的专业软件。对sql server进行可视化管理这款navicat for sql server 12是一款非常不错的软件。  QQ2017
QQ2017 微信电脑版
微信电脑版 阿里旺旺
阿里旺旺 搜狗拼音
搜狗拼音 百度拼音
百度拼音 极品五笔
极品五笔 百度杀毒
百度杀毒 360杀毒
360杀毒 360安全卫士
360安全卫士 谷歌浏览器
谷歌浏览器 360浏览器
360浏览器 搜狗浏览器
搜狗浏览器 迅雷9
迅雷9 IDM下载器
IDM下载器 维棠flv
维棠flv 微软运行库
微软运行库 Winrar压缩
Winrar压缩 驱动精灵
驱动精灵