

![飞速空号筛选软件[手机空号检测工具] V3.1 绿色版](http://pic.9upk.com/soft/UploadPic/2015-11/201511208234420352.gif)


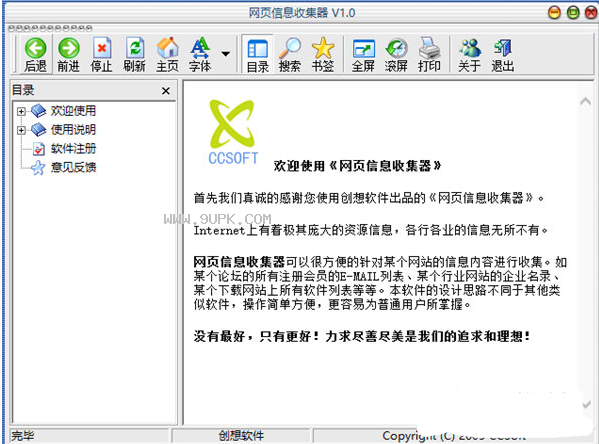
网页信息收集器是一款网站站长会非常喜欢的网页信息抓取工具。如果你是一名网站站长,那么这款 网页信息收集器 相信你一定不会错过的~该软件可以很方便的针对某个网站的信息内容进行收集。需要的快来久友下载站下载使用吧!
功能特色:
1、执行任务
根据已建立的任务信息保存、提取网页,也可通过“双击”某项任务启动此功能
2、新建、复制、修改、删除任务
新建、复制、修改、删除任务信息
3、默认选项
设置默认工作路径(默认为当前程序目录下的WorkDir文件夹)
设置默认提取测试数 (默认为10)
设置默认文本分隔符 (默认为 *)
4、新建、编辑任务信息
任务名称:在默认的工作文件夹下生成以此命名的文件夹。
登录地址:针对某些需要登录才能查看其网页内容的网站,填写登录页面地址。在执行任务时,软件会打开此登录页面让您登录该网站
序数格式类型网页、非序数格式类型网:
这里的序数格式、非序数格式主要是指提取地址是否仅仅是数字的变化。例如类似于:
①http://xxx.com/1.html 和 http://xxx.com/2.html 就属于序数格式
②http://xxx.com/abc.html 和 http://xxx.com/def.html 则属于非序数格式
列表地址:在类型为“非序数格式类型网”时,第一页列表的链接地址
提取地址:由实际保存的网页地址共同部分 + * 号组成。
例如要提取:
①http://xxx.com/1.html 和 http://xxx.com/2.html 则提取地址为 http://xxx.com/*.html
②http://abc.xxx.com/abc.html 和 http://test.xxx.com/def.html 则提取地址为 http://*.xxx.com/*.html
翻页地址:为列表网页上的“下一页”链接地址,将其中变化的部分用 * 号代替。
页数起始:要开始提取的页数
页数截止:要停止提取的页数
当前页数:当前已经提取到的页数
已保存网页数:已经保存的网页数
任务详细描述:该任务的详细描述信息

 onekey一键还原 8.2.4最新版
onekey一键还原 8.2.4最新版 猎豹免费WiFi 5.1.16041115官方正式版
猎豹免费WiFi 5.1.16041115官方正式版 160wifi无线路由软件 4.2.0.4最新版
160wifi无线路由软件 4.2.0.4最新版 pp助手 5.2.0.2798最新正式版
pp助手 5.2.0.2798最新正式版 百度输入法win10版
百度输入法win10版![桌面百度软件[百度桌面搜索工具] V3.0.0.2781 免费版](http://pic.9upk.com/soft/softico/2016-3/20163249251986748.jpg) 桌面百度软件[百度桌面搜索工具] V3.0.0.2781 免费版
桌面百度软件[百度桌面搜索工具] V3.0.0.2781 免费版![WPS Office 2016无广告版[WPS2016官方版] 10.1.0.5975 免安装版](http://pic.9upk.com/soft/softico/2016-5/20165279362197118.png) WPS Office 2016无广告版[WPS2016官方版] 10.1.0.5975 免安装版
WPS Office 2016无广告版[WPS2016官方版] 10.1.0.5975 免安装版 万能五笔输入法
万能五笔输入法 网易云音乐电脑版
网易云音乐电脑版 小皮助手 3.7.5.27官方版
小皮助手 3.7.5.27官方版 驱动精灵
驱动精灵![QQ浏览器 9.3.6582正式免安装版[双核浏览模式]](http://pic.9upk.com/soft/softico/2016-5/20165279391078287.png) QQ浏览器 9.3.6582正式免安装版[双核浏览模式]
QQ浏览器 9.3.6582正式免安装版[双核浏览模式] 青苹果新店云提取系统(青苹果淘宝新开店铺云提取器)是一款可以一键自动提取最新的淘宝新开店铺的工具,由我们云系统自动处理,几乎与淘宝同步,一般来说只要淘宝新开了店铺,基本上在几秒云系统就会自动同步过来。
淘宝...
青苹果新店云提取系统(青苹果淘宝新开店铺云提取器)是一款可以一键自动提取最新的淘宝新开店铺的工具,由我们云系统自动处理,几乎与淘宝同步,一般来说只要淘宝新开了店铺,基本上在几秒云系统就会自动同步过来。
淘宝...  易点投票在线是一款免费实用的在线投票软件,软件功能强大,能够提供投票网站、服务器简单部署、投票快速创建等实用功能。软件方便简单,适用于各行业通过局域网或互联网进行在线投票,需要的话可以来下载使用。
软件...
易点投票在线是一款免费实用的在线投票软件,软件功能强大,能够提供投票网站、服务器简单部署、投票快速创建等实用功能。软件方便简单,适用于各行业通过局域网或互联网进行在线投票,需要的话可以来下载使用。
软件...  31电子签到是一款实用免费的电子签到软件,可以住满足会议现场的电子签到、短信通知、统计分析等基本需要。 它简洁、易用、界面友好。使用者只要具备网络、电脑即可轻松实现高效、准确的签到流程,同时即时掌控现场 ...
31电子签到是一款实用免费的电子签到软件,可以住满足会议现场的电子签到、短信通知、统计分析等基本需要。 它简洁、易用、界面友好。使用者只要具备网络、电脑即可轻松实现高效、准确的签到流程,同时即时掌控现场 ...  华华毫秒点击器是一款十分好用的鼠标连点工具,想要使用这款工具快速进行连续点击的用户赶紧来下载这款点击工具吧,相信一定可以帮到大家。
软件特色:
1、绿色软件,无需安装。
2、支持快捷键操作。
3、间隔时间支持10-...
华华毫秒点击器是一款十分好用的鼠标连点工具,想要使用这款工具快速进行连续点击的用户赶紧来下载这款点击工具吧,相信一定可以帮到大家。
软件特色:
1、绿色软件,无需安装。
2、支持快捷键操作。
3、间隔时间支持10-... 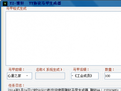 花样马甲生成工具是一款可以帮助大家快速打造直播马甲的工具,想要使用这款马甲生成工具制作马甲的用户赶紧来下载这款软件吧,相信一定可以帮到大家。
软件简介:
是一款针对花样直播打造的马甲名称生成器,能帮助用户...
花样马甲生成工具是一款可以帮助大家快速打造直播马甲的工具,想要使用这款马甲生成工具制作马甲的用户赶紧来下载这款软件吧,相信一定可以帮到大家。
软件简介:
是一款针对花样直播打造的马甲名称生成器,能帮助用户...  QQ2017
QQ2017 微信电脑版
微信电脑版 阿里旺旺
阿里旺旺 搜狗拼音
搜狗拼音 百度拼音
百度拼音 极品五笔
极品五笔 百度杀毒
百度杀毒 360杀毒
360杀毒 360安全卫士
360安全卫士 谷歌浏览器
谷歌浏览器 360浏览器
360浏览器 搜狗浏览器
搜狗浏览器 迅雷9
迅雷9 IDM下载器
IDM下载器 维棠flv
维棠flv 微软运行库
微软运行库 Winrar压缩
Winrar压缩 驱动精灵
驱动精灵